
Zhang et al have written a splendid concise paper that shows how neural networks, even of depth 2, can easily fit random labels from random data.
Furthermore, from their experiments with Inception-like architectures they observe that:
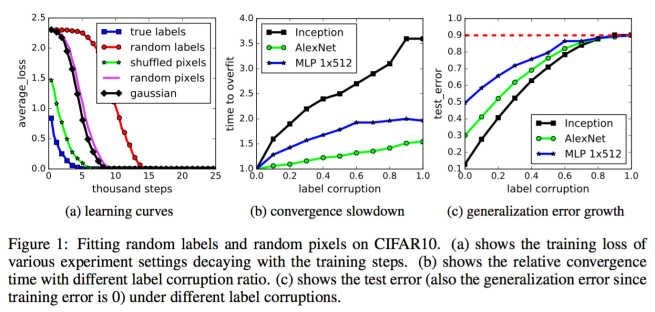
- The effective capacity of neural networks is large enough for a brute force memorization of the entire dataset.
- Even optimization on random labels remains easy. In fact, training time increases only by a small constant factor compare with training on the true labels.
- Randomizing labels is solely a data transformation, leaving all other properties of the learning problem unchanged.
The authors also show that standard generalization theories, such as VC dimension, Rademacher complexity and uniform stability, cannot explain while networks that have the capacity to memorize the entire dataset still can generalize well.
“Explicit regularization may improve performance, but is neither necessary or by itself sufficient for controlling generalization error.”
This paper is one of those rare ones, that in a crystalline way shows our ignorance.
Abstract
Despite their massive size, successful deep artificial neural networks can exhibit a remarkably small difference between training and test performance. Conventional wisdom attributes small generalization error either to properties of the model family, or to the regularization techniques used during training. Through extensive systematic experiments, we show how these traditional approaches fail to explain why large neural networks generalize well in practice. Specifically, our experiments establish that state-of-the-art convolutional networks for image classification trained with stochastic gradient methods easily fit a random labeling of the training data. This phenomenon is qualitatively unaffected by explicit regularization, and occurs even if we replace the true images by completely unstructured random noise. We corroborate these experimental findings with a theoretical construction showing that simple depth two neural networks already have perfect finite sample expressivity as soon as the number of parameters exceeds the number of data points as it usually does in practice. We interpret our experimental findings by comparison with traditional models.

One thought on “Understanding deep learning requires rethinking generalization”